| 메타 문자 | 설명 |
| [] | 문자, 숫자 범위를 표현하며 +, -, . 등의 기호를 포함할 수 있음 |
| {개수} | 특정 개수의 문자, 숫자를 표현 |
| {시작개수, 끝개수} | 특정 개수 범위의 문자, 숫자를 표현 |
| + | 1개 이상의 문자를 표현. 예) a+b는 ab, aab, aaab는 되지만 b는 안 됨 |
| * | 0개 이상의 문자를 표현. 예) a*b는 b, ab, aab, aaab |
| ? | 0개 또는 1개의 문자를 표현. 예) a?b는 b, ab |
| . | 문자 1개만 표현 |
| ^ | [ ] 앞에 붙이면 특정 문자 범위로 시작하는지 판단 |
| [ ] 안에 넣으면 특정 문자 범위를 제외 | |
| $ | 특정 문자 범위로 끝나는지 판단 |
| | | 여러 문자열 중 하나라도 포함되는지 판단 |
| ( ) | 정규표현식을 그룹으로 묶음, 그룹에 이름을 지을 때는 ?P<이름> 형식 |
| 예) (?P<func>[a-zA-Z_][a-zA-Z0-9_]+) |
| 함수 및 메서드 | 설명 |
| match('패턴', '문자열') | 문자열의 시작부터 패턴에 매칭되는지 판단, 매칭되면 매치 객체 반환 |
| search('패턴', '문자열') | 문자열의 일부분이 패턴에 매칭되는지 판단, 매칭되면 매치 객체 반환 |
| group(그룹) | 그룹에 매칭된 문자열 반환 |
| groups() | 각 그룹에 해당하는 문자열을 튜플로 반환 |
| findall('패턴', '문자열') | 패턴에 매칭된 문자열을 리스트로 반환 |
| sub('패턴', '바꿀문자열', '문자열', 바꿀횟수) | 패턴으로 특정 문자열을 찾은 뒤 다른 문자열로 바꿈, 찾은 문자열을 사용하려면 바꿀 문자열에서 \\숫자 형식으로 사용, 그룹에 이름을 지었다면 \\g<이름> 형식으로 사용(\\g<숫자> 형식도 가능). |
| 예) re.sub('(\w+) (?P<x>\d+)', '\\g<x> \\1', 'Hello 1234') | |
| compile('패턴') | 정규표현식 패턴을 객체로 만듦 |
| match('문자열') | 문자열의 시작부터 패턴에 매칭되는지 판단, 매칭되면 매치 객체 반환 |
| search('문자열') | 문자열의 일부분이 패턴에 매칭되는지 판단, 매칭되면 매치 객체 반환 |
| 특수 문자 | 설명 |
| \ | 정규표현식에서 사용하는 문자를 그대로 표현하려면 앞에 \를 붙임. 예) \+, \* |
| \d | [0-9]와 같음. 모든 숫자 |
| \D | [^0-9]와 같음. 숫자를 제외한 모든 문자 |
| \w | [a-zA-Z0-9_]와 같음. 영문 대소문자, 숫자, 밑줄 문자 |
| \W | [^a-zA-Z0-9_]와 같음. 영문 대소문자, 숫자, 밑줄 문자를 제외한 모든 문자 |
| \s | [ \t\n\r\f\v]와 같음. 공백(스페이스), \t, \n, \r, \f, \v을 포함 |
| \S | [^ \t\n\r\f\v]와 같음. 공백을 제외하고 \t, \n, \r, \f, \v만 포함 |
43.1 문자열 판단하기
Unit 43. 정규표현식 사용하기
정규표현식(regular expression)은 일정한 규칙(패턴)을 가진 문자열을 표현하는 방법입니다. 복잡한 문자열 속에서 특정한 규칙으로 된 문자열을 검색한 뒤 추출하거나 바꿀 때 사용합니다. 또는, 문자열이 정해진 규칙에 맞는지 판단할 때도 사용합니다.
정규표현식을 처음 접하면 외계어 같아서 어려워하는 사람들이 많습니다. 하지만 부분부분 쪼개서 학습하면 그렇게 어렵지 않습니다.
43.1 문자열 판단하기
간단하게 문자열에 특정 문자열이 포함되어 있는지 판단해보겠습니다. 정규표현식은 re 모듈을 가져와서 사용하며 match 함수에 정규표현식 패턴과 판단할 문자열을 넣습니다(re는 regular expression의 약자).
- re.match('패턴', '문자열')
다음은 'Hello, world!' 문자열에 'Hello'와 'Python'이 있는지 판단합니다.
>>> import re
>>> re.match('Hello', 'Hello, world!') # 문자열이 있으므로 정규표현식 매치 객체가 반환됨
<_sre.SRE_Match object; span=(0, 5), match='Hello'>
>>> re.match('Python', 'Hello, world!') # 문자열이 없으므로 아무것도 반환되지 않음
문자열이 있으면 매치(SRE_Match) 객체가 반환되고 없으면 아무것도 반환되지 않습니다. 여기서는 'Hello'가 있으므로 match='Hello'와 같이 패턴에 매칭된 문자열이 표시됩니다.
사실 이런 판단은 'Hello, world!'.find('Hello')처럼 문자열 메서드로도 충분히 가능합니다. 이제부터 문자열 메서드로 할 수 없는 판단을 해보겠습니다.
43.1.1 문자열이 맨 앞에 오는지 맨 뒤에 오는지 판단하기
정규표현식은 특정 문자열이 맨 앞에 오는지 맨 뒤에 오는지 판단할 수 있습니다.
문자열 앞에 ^를 붙이면 문자열이 맨 앞에 오는지 판단하고, 문자열 뒤에 $를 붙이면 문자열이 맨 뒤에 오는지 판단합니다(특정 문자열로 끝나는지).
- ^문자열
- 문자열$
단, 이때는 match 대신 search 함수를 사용해야 합니다. match 함수는 문자열 처음부터 매칭되는지 판단하지만, search는 문자열 일부분이 매칭되는지 판단합니다.
- re.search('패턴', '문자열')
'^Hello'는 'Hello, world!'가 'Hello'로 시작하는지 판단하고, 'world!$'는 'Hello, world!'가 'world!'로 끝나는지 판단합니다.
>>> re.search('^Hello', 'Hello, world!') # Hello로 시작하므로 패턴에 매칭됨
<_sre.SRE_Match object; span=(0, 5), match='Hello'>
>>> re.search('world!$', 'Hello, world!') # world!로 끝나므로 패턴에 매칭됨
<_sre.SRE_Match object; span=(7, 13), match='world!'>
43.1.2 지정된 문자열이 하나라도 포함되는지 판단하기
|는 특정 문자열에서 지정된 문자열(문자)이 하나라도 포함되는지 판단합니다. 기본 개념은 OR 연산자와 같습니다.
- 문자열|문자열
- 문자열|문자열|문자열|문자열
'hello|world'는 문자열에서 'hello' 또는 'world'가 포함되는지 판단합니다.
>>> re.match('hello|world', 'hello') # hello 또는 world가 있으므로 패턴에 매칭됨
<_sre.SRE_Match object; span=(0, 5), match='hello'>
43.2 범위 판단하기
이번에는 문자열이 숫자로 되어있는지 판단해보겠습니다. 다음과 같이 [ ](대괄호) 안에 숫자 범위를 넣으며 * 또는 +를 붙입니다. 숫자 범위는 0-9처럼 표현하며 *는 문자(숫자)가 0개 이상 있는지, +는 1개 이상 있는지 판단합니다.
- [0-9]*
- [0-9]+
>>> re.match('[0-9]*', '1234') # 1234는 0부터 9까지 숫자가 0개 이상 있으므로 패턴에 매칭됨
<_sre.SRE_Match object; span=(0, 4), match='1234'>
>>> re.match('[0-9]+', '1234') # 1234는 0부터 9까지 숫자가 1개 이상 있으므로 패턴에 매칭됨
<_sre.SRE_Match object; span=(0, 4), match='1234'>
>>> re.match('[0-9]+', 'abcd') # abcd는 0부터 9까지 숫자가 1개 이상 없으므로 패턴에 매칭되지 않음
그럼 *와 +는 어디에 활용할까요? 다음과 같이 a*b와 a+b를 확인해보면 쉽게 알 수 있습니다.
>>> re.match('a*b', 'b') # b에는 a가 0개 이상 있으므로 패턴에 매칭됨
<_sre.SRE_Match object; span=(0, 1), match='b'>
>>> re.match('a+b', 'b') # b에는 a가 1개 이상 없으므로 패턴에 매칭되지 않음
>>> re.match('a*b', 'aab') # aab에는 a가 0개 이상 있으므로 패턴에 매칭됨
<_sre.SRE_Match object; span=(0, 3), match='aab'>
>>> re.match('a+b', 'aab') # aab에는 a가 1개 이상 있으므로 패턴에 매칭됨
<_sre.SRE_Match object; span=(0, 3), match='aab'>
a*b, a+b에서 b는 무조건 있어야 하는 문자고, a*는 a가 0개 이상 있어야 하므로 b는 매칭이 됩니다. 하지만 a+는 a가 1개 이상 있어야 하므로 b는 매칭되지 않습니다. 그리고 'ab', 'aab', 'aaab'처럼 a가 0개 이상 또는 1개 이상 있을 때는 a*b와 a+b를 모두 만족합니다.
43.2.1 문자가 한 개만 있는지 판단하기
문자가 여러 개 있는지 판단할 때는 *과 +를 사용했지만, 문자가 한 개만 있는지 판단할 때는 어떻게 해야 할까요? 이때는 ?와 .을 사용합니다. ?는 ? 앞의 문자(범위)가 0개 또는 1개인지 판단하고, .은 .이 있는 위치에 아무 문자(숫자)가 1개 있는지 판단합니다.
- 문자?
- [0-9]?
- .
>>> re.match('abc?d', 'abd') # abd에서 c 위치에 c가 0개 있으므로 패턴에 매칭됨
<_sre.SRE_Match object; span=(0, 3), match='abd'>
>>> re.match('ab[0-9]?c', 'ab3c') # [0-9] 위치에 숫자가 1개 있으므로 패턴에 매칭됨
<_sre.SRE_Match object; span=(0, 4), match='ab3c'>
>>> re.match('ab.d', 'abxd') # .이 있는 위치에 문자가 1개 있으므로 패턴에 매칭됨
<_sre.SRE_Match object; span=(0, 4), match='abxd'>
43.2.2 문자 개수 판단하기
그럼 문자(숫자)가 정확히 몇 개 있는지 판단하고 싶을 수도 있겠죠? 이때는 문자 뒤에 {개수} 형식을 지정합니다. 문자열의 경우에는 문자열을 괄호로 묶고 뒤에 {개수} 형식을 지정합니다.
- 문자{개수}
- (문자열){개수}
h{3}은 h가 3개 있는지 판단하고, (hello){3}은 hello가 3개 있는지 판단합니다.
>>> re.match('h{3}', 'hhhello')
<_sre.SRE_Match object; span=(0, 3), match='hhh'>
>>> re.match('(hello){3}', 'hellohellohelloworld')
<_sre.SRE_Match object; span=(0, 15), match='hellohellohello'>
특정 범위의 문자(숫자)가 몇 개 있는지 판단할 수도 있습니다. 이때는 범위 [ ] 뒤에 {개수} 형식을 지정합니다.
- [0-9]{개수}
다음은 휴대전화의 번호 형식에 맞는지 판단합니다.
>>> re.match('[0-9]{3}-[0-9]{4}-[0-9]{4}', '010-1000-1000') # 숫자 3개-4개-4개 패턴에 매칭됨
<_sre.SRE_Match object; span=(0, 13), match='010-1000-1000'>
>>> re.match('[0-9]{3}-[0-9]{4}-[0-9]{4}', '010-1000-100') # 숫자 3개-4개-4개 패턴에 매칭되지 않음
이 기능은 문자(숫자)의 개수 범위도 지정할 수 있습니다. {시작개수,끝개수} 형식으로 시작 개수와 끝 개수를 지정해주면 특정 개수 사이에 들어가는지 판단합니다.
- (문자){시작개수,끝개수}
- (문자열){시작개수,끝개수}
- [0-9]{시작개수,끝개수}
다음은 일반전화의 번호 형식에 맞는지 판단합니다.
>>> re.match('[0-9]{2,3}-[0-9]{3,4}-[0-9]{4}', '02-100-1000') # 2~3개-3~4개-4개 패턴에 매칭됨
<_sre.SRE_Match object; span=(0, 11), match='02-100-1000'>
>>> re.match('[0-9]{2,3}-[0-9]{3,4}-[0-9]{4}', '02-10-1000') # 2~3개-3~4개-4개 패턴에 매칭되지 않음
43.2.3 숫자와 영문 문자를 조합해서 판단하기
지금까지 숫자 범위만 판단해보았으니 이제 숫자와 영문 문자를 조합해서 판단해보겠습니다. 영문 문자 범위는 a-z, A-Z와 같이 표현합니다.
- a-z
- A-Z
>>> re.match('[a-zA-Z0-9]+', 'Hello1234') # a부터 z, A부터 Z, 0부터 9까지 1개 이상 있으므로
<_sre.SRE_Match object; span=(0, 9), match='Hello1234'> # 패턴에 매칭됨
>>> re.match('[A-Z0-9]+', 'hello') # 대문자, 숫자는 없고 소문자만 있으므로 패턴에 매칭되지 않음
이처럼 숫자, 영문 문자 범위는 a-zA-Z0-9 또는 A-Z0-9와 같이 붙여 쓰면 됩니다.
그럼 한글은 어떻게 사용할까요? 영문 문자와 방법이 같습니다. 가-힣처럼 나올 수 있는 한글 조합을 정해주면 됩니다.
- 가-힣
>>> re.match('[가-힣]+', '홍길동') # 가부터 힣까지 1개 이상 있으므로 패턴에 매칭됨
<_sre.SRE_Match object; span=(0, 3), match='홍길동'>
43.2.4 특정 문자 범위에 포함되지 않는지 판단하기
지금까지 정규표현식으로 특정 문자 범위에 포함되는지 살펴보았습니다. 그럼 특정 문자 범위에 포함되지 않는지 판단하려면 어떻게 해야 할까요? 다음과 같이 문자(숫자) 범위 앞에 ^를 붙이면 해당 범위를 제외합니다.
- [^범위]*
- [^범위]+
즉, '[^A-Z]+'는 대문자를 제외한 모든 문자(숫자)가 1개 이상 있는지 판단합니다.
>>> re.match('[^A-Z]+', 'Hello') # 대문자를 제외. 대문자가 있으므로 패턴에 매칭되지 않음
>>> re.match('[^A-Z]+', 'hello') # 대문자를 제외. 대문자가 없으므로 패턴에 매칭됨
<_sre.SRE_Match object; span=(0, 5), match='hello'>
앞에서 특정 문자열로 시작하는지 판단할 때도 ^를 사용했었는데 문법이 비슷해서 이 부분은 헷갈리기 쉽습니다. 범위를 제외할 때는 '[^A-Z]+'와 같이 [ ] 안에 넣어주고, 특정 문자 범위로 시작할 때는 '^[A-Z]+'와 같이 [ ] 앞에 붙여줍니다. 그래서 다음과 같이 '^[A-Z]+'는 영문 대문자로 시작하는지 판단합니다.
- ^[범위]*
- ^[범위]+
>>> re.search('^[A-Z]+', 'Hello') # 대문자로 시작하므로 패턴에 매칭됨
<_sre.SRE_Match object; span=(0, 1), match='H'>
물론 특정 문자(숫자) 범위로 끝나는지 확인할 때는 정규표현식 뒤에 $를 붙이면 됩니다.
- [범위]*$
- [범위]+$
>>> re.search('[0-9]+$', 'Hello1234') # 숫자로 끝나므로 패턴에 매칭됨
<_sre.SRE_Match object; span=(5, 9), match='1234'>
43.2.5 특수 문자 판단하기
문자열을 판단할 때 'Hello1234'처럼 평범한 문자열만 판단했습니다. 그런데 정규표현식에 사용하는 특수 문자 *, +, ?, ., ^, $, (, ) [, ], - 등을 판단하려면 어떻게 해야 할까요? 특수 문자를 판단할 때는 특수 문자 앞에 \를 붙이면 됩니다. 단, [ ] 안에서는 \를 붙이지 않아도 되지만 에러가 발생하는 경우에는 \를 붙입니다.
- \특수문자
>>> re.search('\*+', '1 ** 2') # *이 들어있는지 판단
<_sre.SRE_Match object; span=(2, 4), match='**'>
>>> re.match('[$()a-zA-Z0-9]+', '$(document)') # $, (, )와 문자, 숫자가 들어있는지 판단
<_sre.SRE_Match object; span=(0, 11), match='$(document)'>
지금까지 범위를 지정하면서 a-zA-Z0-9처럼 대소문자와 숫자를 모두 나열했습니다. 이런 방식으로 범위를 정하면 정규표현식이 길어지고 복잡해집니다. 단순히 숫자인지 문자인지 판단할 때는 \d, \D, \w, \W를 사용하면 편리합니다.
- \d: [0-9]와 같음. 모든 숫자
- \D: [^0-9]와 같음. 숫자를 제외한 모든 문자
- \w: [a-zA-Z0-9_]와 같음. 영문 대소문자, 숫자, 밑줄 문자
- \W: [^a-zA-Z0-9_]와 같음. 영문 대소문자, 숫자, 밑줄 문자를 제외한 모든 문자
>>> re.match('\d+', '1234') # 모든 숫자이므로 패턴에 매칭됨
<_sre.SRE_Match object; span=(0, 4), match='1234'>
>>> re.match('\D+', 'Hello') # 숫자를 제외한 모든 문자이므로 패턴에 매칭됨
<_sre.SRE_Match object; span=(0, 5), match='Hello'>
>>> re.match('\w+', 'Hello_1234') # 영문 대소문자, 숫자, 밑줄 문자이므로 패턴에 매칭됨
<_sre.SRE_Match object; span=(0, 10), match='Hello_1234'>
>>> re.match('\W+', '(:)') # 영문 대소문자, 숫자, 밑줄문자를 제외한 모든 문자이므로 패턴에 매칭됨
<_sre.SRE_Match object; span=(0, 3), match='(:)'>
43.2.6 공백 처리하기
이번에는 공백을 처리해보겠습니다. 공백은 ' '처럼 공백 문자를 넣어도 되고, \s 또는 \S로 표현할 수도 있습니다.
- \s: [ \t\n\r\f\v]와 같음. 공백(스페이스), \t(탭) \n(새 줄, 라인 피드), \r(캐리지 리턴), \f(폼피드), \v(수직 탭)을 포함
- \S: [^ \t\n\r\f\v]와 같음. 공백을 제외하고 \t, \n, \r, \f, \v만 포함
>>> re.match('[a-zA-Z0-9 ]+', 'Hello 1234') # ' '로 공백 표현
<_sre.SRE_Match object; span=(0, 10), match='Hello 1234'>
>>> re.match('[a-zA-Z0-9\s]+', 'Hello 1234') # \s로 공백 표현
<_sre.SRE_Match object; span=(0, 10), match='Hello 1234'>
매번 match나 search 함수에 정규표현식 패턴을 지정하는 방법은 비효율적입니다. 같은 패턴을 자주 사용할 때는 compile 함수를 사용하여 정규표현식 패턴을 객체로 만든 뒤 match 또는 search 메서드를 호출하면 됩니다.
객체 = re.compile('패턴')
객체.match('문자열')
객체.search('문자열')
>>> p = re.compile('[0-9]+') # 정규표현식 패턴을 객체로 만듦
>>> p.match('1234') # 정규표현식 패턴 객체에서 match 메서드 사용
<_sre.SRE_Match object; span=(0, 4), match='1234'>
>>> p.search('hello') # 정규표현식 패턴 객체에서 search 메서드 사용
43.3 그룹 사용하기
지금까지 정규표현식 하나로만 매칭 여부를 판단했습니다. 이번에는 정규표현식을 그룹으로 묶는 방법을 알아보겠습니다. 정규표현식 그룹은 해당 그룹과 일치하는 문자열을 얻어올 때 사용합니다.
패턴 안에서 정규표현식을 ( )(괄호)로 묶으면 그룹이 됩니다.
- (정규표현식) (정규표현식)
다음은 공백으로 구분된 숫자를 두 그룹으로 나누어서 찾은 뒤 각 그룹에 해당하는 문자열(숫자)을 가져옵니다.
- 매치객체.group(그룹숫자)
>>> m = re.match('([0-9]+) ([0-9]+)', '10 295')
>>> m.group(1) # 첫 번째 그룹(그룹 1)에 매칭된 문자열을 반환
'10'
>>> m.group(2) # 두 번째 그룹(그룹 2)에 매칭된 문자열을 반환
'295'
>>> m.group() # 매칭된 문자열을 한꺼번에 반환
'10 295'
>>> m.group(0) # 매칭된 문자열을 한꺼번에 반환
'10 295'
매치 객체의 group 메서드에 숫자를 지정하면 해당 그룹에 매칭된 문자열을 반환합니다. 숫자를 지정하지 않거나 0을 지정하면 매칭된 문자열을 한꺼번에 반환합니다.
그리고 groups 메서드는 각 그룹에 해당하는 문자열을 튜플로 반환합니다.
- 매치객체.groups()
>>> m.groups() # 각 그룹에 해당하는 문자열을 튜플 형태로 반환
('10', '295')
그룹 개수가 많아지면 숫자로 그룹을 구분하기가 힘들어집니다. 이때는 그룹에 이름을 지으면 편리합니다. 그룹의 이름은 ( )(괄호) 안에 ?P<이름> 형식으로 지정합니다.
- (?P<이름>정규표현식)
다음은 함수를 호출하는 코드 print(1234)에서 함수의 이름 print와 인수 1234를 추출합니다.
- 매치객체.group('그룹이름')
>>> m = re.match('(?P<func>[a-zA-Z_][a-zA-Z0-9_]+)\((?P<arg>\w+)\)', 'print(1234)')
>>> m.group('func') # 그룹 이름으로 매칭된 문자열 출력
'print'
>>> m.group('arg') # 그룹 이름으로 매칭된 문자열 출력
'1234'
(?P<func>)와 (?P<arg>)처럼 각 그룹에 이름을 짓고 m.group('func'), m.group('arg')로 매칭된 문자열을 출력했습니다. 참고로 함수 이름은 문자로만 시작해야 하므로 첫글자는 [a-zA-Z_]로 판단해줍니다. 또한, print 뒤에 붙은 (, )는 정규표현식에 사용하는 특수 문자이므로 앞에 \를 붙여줍니다.
43.3.1 패턴에 매칭되는 모든 문자열 가져오기
지금까지 그룹에 해당하는 문자열을 가져왔습니다. 그러면 그룹 지정 없이 패턴에 매칭되는 모든 문자열을 가져오려면 어떻게 해야 할까요? 이때는 findall 함수를 사용하며 매칭된 문자열을 리스트로 반환합니다.
- re.findall('패턴', '문자열')
다음은 문자열에서 숫자만 가져옵니다.
>>> re.findall('[0-9]+', '1 2 Fizz 4 Buzz Fizz 7 8')
['1', '2', '4', '7', '8']
정규표현식에서 +과 *을 조합하여 사용할 때는 그룹으로 묶어서 사용합니다. (.[a-z]+)*는 점과 영문 소문자가 1개 이상 있는지 판단하고, 이것 자체가 0개 이상인지 판단합니다. 즉, 규칙은 반드시 지켜야 하지만 있어도 되고 없어도 되는 상황에 사용합니다.
>>> re.match('[a-z]+(.[a-z]+)*$', 'hello.world') # .world는 문자열이므로 패턴에 매칭됨
<_sre.SRE_Match object; span=(0, 11), match='hello.world'>
>>> re.match('[a-z]+(.[a-z]+)*$', 'hello.1234') # .1234는 숫자이므로 패턴에 매칭되지 않음
>>> re.match('[a-z]+(.[a-z]+)*$', 'hello') # .뒤에 문자열이 없어도 패턴에 매칭됨
<_sre.SRE_Match object; span=(0, 5), match='hello'>
43.4 문자열 바꾸기
이번에는 정규표현식으로 특정 문자열을 찾은 뒤 다른 문자열로 바꾸는 방법을 알아보겠습니다. 문자열을 바꿀 때는 sub 함수를 사용하며 패턴, 바꿀 문자열, 문자열, 바꿀 횟수를 넣어줍니다. 여기서 바꿀 횟수를 넣으면 지정된 횟수만큼 바꾸며 바꿀 횟수를 생략하면 찾은 문자열을 모두 바꿉니다.
- re.sub('패턴', '바꿀문자열', '문자열', 바꿀횟수)
다음은 문자열에서 'apple' 또는 'orange'를 찾아서 'fruit'로 바꿉니다.
>>> re.sub('apple|orange', 'fruit', 'apple box orange tree') # apple 또는 orange를 fruit로 바꿈
'fruit box fruit tree'
또는, 문자열에서 숫자만 찾아서 다른 문자로 바꿀 수도 있겠죠? 다음은 숫자만 찾아서 'n'으로 바꿉니다.
>>> re.sub('[0-9]+', 'n', '1 2 Fizz 4 Buzz Fizz 7 8') # 숫자만 찾아서 n으로 바꿈
'n n Fizz n Buzz Fizz n n'
sub 함수는 바꿀 문자열 대신 교체 함수를 지정할 수도 있습니다. 교체 함수는 매개변수로 매치 객체를 받으며 바꿀 결과를 문자열로 반환하면 됩니다. 다음은 문자열에서 숫자를 찾은 뒤 숫자를 10배로 만듭니다.
- 교체함수(매치객체)
- re.sub('패턴', 교체함수, '문자열', 바꿀횟수)
>>> def multiple10(m): # 매개변수로 매치 객체를 받음
... n = int(m.group()) # 매칭된 문자열을 가져와서 정수로 변환
... return str(n * 10) # 숫자에 10을 곱한 뒤 문자열로 변환해서 반환
...
>>> re.sub('[0-9]+', multiple10, '1 2 Fizz 4 Buzz Fizz 7 8')
'10 20 Fizz 40 Buzz Fizz 70 80'
mutiple10 함수에서 group 메서드로 매칭된 문자열을 가져와서 정수로 바꿉니다. 그리고 숫자에 10을 곱한 뒤 문자열로 변환해서 반환했습니다.
교체 함수의 내용이 간단하다면 다음과 같이 람다 표현식을 만들어서 넣어도 됩니다.
>>> re.sub('[0-9]+', lambda m: str(int(m.group()) * 10), '1 2 Fizz 4 Buzz Fizz 7 8')
'10 20 Fizz 40 Buzz Fizz 70 80'
43.4.1 찾은 문자열을 결과에 다시 사용하기
이번에는 정규표현식으로 찾은 문자열을 가져와서 결과에 다시 사용해보겠습니다. 먼저 정규표현식을 그룹으로 묶습니다. 그러고 나면 바꿀 문자열에서 \\숫자 형식으로 매칭된 문자열을 가져와서 사용할 수 있습니다.
- \\숫자
다음은 'hello 1234'에서 hello는 그룹 1, 1234는 그룹 2로 찾은 뒤 그룹 2, 1, 2, 1 순으로 문자열의 순서를 바꿔서 출력합니다.
>>> re.sub('([a-z]+) ([0-9]+)', '\\2 \\1 \\2 \\1', 'hello 1234') # 그룹 2, 1, 2, 1 순으로 바꿈
'1234 hello 1234 hello'
이번에는 조금 더 응용해보겠습니다. 다음은 '{ "name": "james" }'을 '<name>james</name>' 형식으로 바꿉니다.
>>> re.sub('({\s*)"(\w+)":\s*"(\w+)"(\s*})', '<\\2>\\3</\\2>', '{ "name": "james" }')
'<name>james</name>'
외계어처럼 보이지만 부분부분 나눠서 보면 어렵지 않습니다. 이 정규표현식에서 그룹은 4개입니다. 맨 처음 ({\s*)은 {와 공백을 찾으므로 '{ '을 찾습니다. 그리고 마지막 (\s*})은 공백과 }를 찾으므로 ' }'를 찾습니다. 중간에 있는 "(\w+)":\s*"(\w+)"은 :을 기준으로 양 옆의 name과 james를 찾습니다. 바꿀 문자열은 '<\\2>'과 같이 그룹 2 name과 그룹 3 james만 사용하고 그룹 1 '{ ', 그룹 4 '} '는 버립니다.
▼ 그림 43-1 정규 표현식으로 찾은 문자열을 사용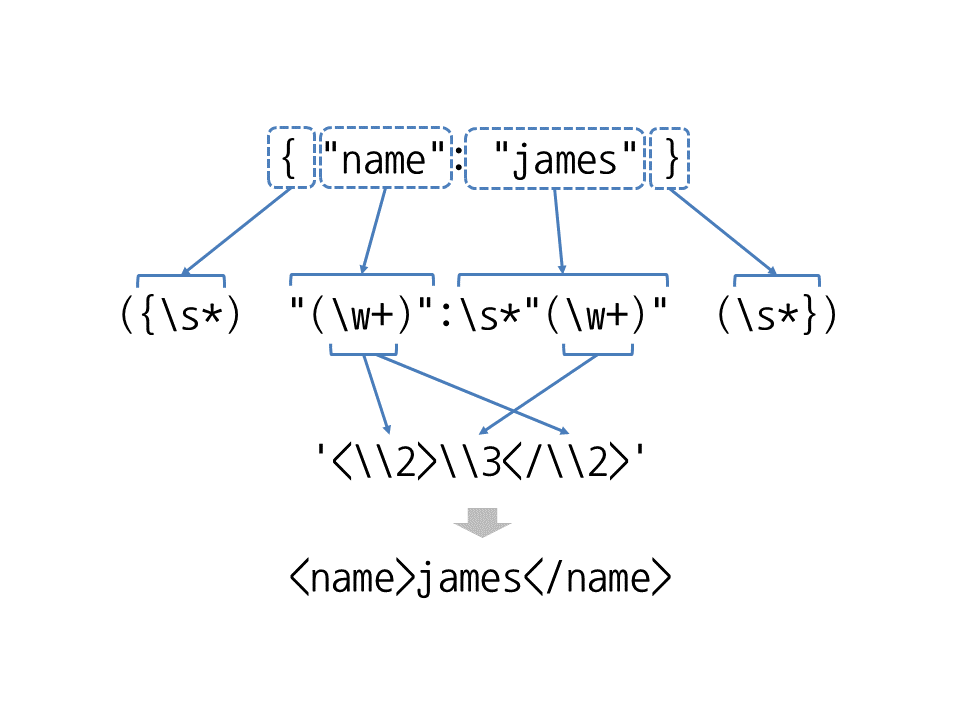
만약 그룹에 이름을 지었다면 \\g<이름> 형식으로 매칭된 문자열을 가져올 수 있습니다(\\g<숫자> 형식으로 숫자를 지정해도 됩니다).
- \\g<이름>
- \\g<숫자>
>>> re.sub('({\s*)"(?P<key>\w+)":\s*"(?P<value>\w+)"(\s*})', '<\\g<key>>\\g<value></\\g<key>>', '{ "name": "james" }')
'<name>james</name>'
지금까지 정규표현식에 대해 배웠습니다. 정규표현식은 특수 문자가 많이 쓰이고, 복잡해 보여서 많은 사람들이 어려워하는 분야입니다. 지금 당장은 모든 내용을 외울 필요는 없습니다. 나중에 정규표현식이 필요할 때 다시 돌아와서 찾아보면 됩니다. 여기서 소개한 정규표현식 패턴은 핵심 정리에 정리되어 있습니다.
정규표현식의 특수 문자를 판단하려면 \를 붙여야 합니다. 여기서 문자열 앞에 r을 붙여주면 원시(raw) 문자열이 되어 \를 붙이지 않아도 특수 문자를 그대로 판단할 수 있습니다. 따라서 raw 문자열에서는 \\숫자, \\g<이름>, \\g<숫자>는 \숫자, \g<이름>, \g<숫자> 형식처럼 \를 하나만 붙여서 사용할 수 있습니다.
r'\숫자 \g<이름> \g<숫자>'
>>> re.sub('({\s*)"(\w+)":\s*"(\w+)"(\s*})', r'<\2>\3</\2>', '{ "name": "james" }')
'<name>james</name>'
다음 소스 코드를 완성하여 주어진 이메일 주소가 올바른지 판단하도록 만드세요. emails 리스트에서 앞의 다섯 개는 올바른 형식이며 마지막 세 개는 잘못된 형식입니다.
practice_regular_expression.py
import re
p = re.compile( )
emails = ['python@mail.example.com', 'python+kr@example.com', # 올바른 형식
'python-dojang@example.co.kr', 'python_10@example.info', # 올바른 형식
'python.dojang@e-xample.com', # 올바른 형식
'@example.com', 'python@example', 'python@example-com'] # 잘못된 형식
for email in emails:
print(p.match(email) != None, end=' ')
실행 결과
True True True True True False False False
정답
'^[a-zA-Z0-9+-_.]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+$'
표준 입력으로 URL 문자열이 입력 입력됩니다. 입력된 URL이 올바르면 True, 잘못되었으면 False를 출력하는 프로그램을 만드세요. 이 심사문제에서 판단해야 할 URL의 규칙은 다음과 같습니다.
- http:// 또는 https://로 시작
- 도메인은 도메인.최상위도메인 형식이며 영문 대소문자, 숫자, -로 되어 있어야 함
- 도메인 이하 경로는 /로 구분하고, 영문 대소문자, 숫자, -, _, ., ?, =을 사용함
judge_regular_expression.py
________________________________
________________________________
________________________________
예입력
결과
입력
결과
import re
exp = '^https?://[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+/[a-zA-Z0-9-_/.?=]*'
p = re.compile(exp)
url = input()
print(p.match(url) != None)



댓글