1. 문자열
'(작은따옴표), "(큰따옴표)를 사용하여 만든다.
여러줄 문자열 생성 - """여러줄 문자열"""
'''여러줄 문자열'''
문자열내 작은따옴표,큰따옴표가 있으면 그외 기호로 문자열을 묶어주거나 \' 나 \" 처럼 escape문자 사용하라!!!
>>> s = "Python isn't difficult"
>>> s
"Python isn't difficult">>> 'Python isn\'t difficult'
"Python isn't difficult"
2. 리스트
빈 리스트
- 리스트 = []
- 리스트 = list()
>>> a = []
>>> a
[]
>>> b = list()
>>> b
[]
range를 이용한 리스트 만들기
- range(횟수)
>>> range(10)
range(0, 10)- 리스트 = list(range(횟수))
>>> a = list(range(10))
>>> a
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
- 리스트 = list(range(시작, 끝))
>>> b = list(range(5, 12))
>>> b
[5, 6, 7, 8, 9, 10, 11]
- 리스트 = list(range(시작, 끝, 증가폭))
>>> c = list(range(-4, 10, 2))
>>> c
[-4, -2, 0, 2, 4, 6, 8]
3. 튜플
요소가 한 개 들어있는 튜플 만들기
- 튜플 = (값, )
- 튜플 = 값,
>>> (38, )
(38,)
>>> 38,
(38,)
리스트 언패킹(list unpacking), 튜플 언패킹(tuple unpacking)
리스트와 튜플을 사용하면 변수 여러 개를 한 번에 만들 수 있습니다. 이때 변수의 개수와 리스트(튜플)의 요소 개수는 같아야 합니다.
>>> a, b, c = [1, 2, 3]
>>> print(a, b, c)
1 2 3
>>> d, e, f = (4, 5, 6)
>>> print(d, e, f)
4 5 6
리스트와 튜플 변수로도 변수 여러 개를 만들 수 있습니다. 다음과 같이 리스트와 튜플의 요소를 변수 여러 개에 할당하는 것을 리스트 언패킹(list unpacking), 튜플 언패킹(tuple unpacking)이라고 합니다.
4. sequence자료형 특징

1) 특정 값이 있는지 확인
값 in 시퀀스객체
값 not in 시퀀스객체
2) 시퀀스 자료형 연결 : +

3) 시퀀스 자료형 반복하기 : *

3) 시퀀스 자료형 요소개수 구하기 : len함수
>>> a = [0, 10, 20, 30, 40, 50, 60, 70, 80, 90]
>>> len(a)
10
한글문자열도 가능
a="홍길동"
len(a)
3한글, 한자, 일본어 등은 UTF-8 인코딩으로 저장하는데 문자열이 차지하는 실제 바이트 수를 구하는 방법은 다음과 같습니다.
>>> hello = '안녕하세요'
>>> len(hello.encode('utf-8'))
15
UTF-8에서 한글 글자 하나는 3바이트로 표현하므로 '안녕하세요'가 차지하는 실제 바이트 수는 15바이트입니다.
4) indexing
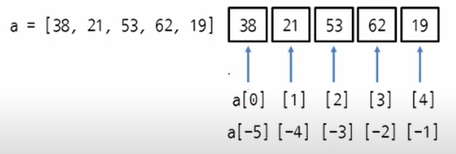
시퀀스 객체에서 [ ](대괄호)를 사용하면 실제로는 __getitem__ 메서드를 호출하여 요소를 가져옵니다. 따라서 다음과 같이 __getitem__ 메서드를 직접 호출하여 요소를 가져올 수도 있습니다.
시퀀스객체.__getitem__(인덱스)
>>> a = [38, 21, 53, 62, 19]
>>> a.__getitem__(1)
21
del로 요소 삭제하기
- del 시퀀스객체[인덱스]
먼저 리스트를 만들고 세 번째 요소(인덱스 2)를 삭제해보겠습니다.
>>> a = [38, 21, 53, 62, 19]
>>> del a[2]
>>> a
[38, 21, 62, 19]4) slicing
- 시퀀스객체[시작인덱스:끝인덱스]
다음은 리스트의 일부를 잘라서 새 리스트를 만듭니다.
>>> a = [0, 10, 20, 30, 40, 50, 60, 70, 80, 90]
>>> a[0:4] # 인덱스 0부터 3까지 잘라서 새 리스트를 만듦
[0, 10, 20, 30]인덱스 증가폭 사용하기
- 시퀀스객체[시작인덱스:끝인덱스:인덱스증가폭]
>>> a = [0, 10, 20, 30, 40, 50, 60, 70, 80, 90]
>>> a[2:8:3] # 인덱스 2부터 3씩 증가시키면서 인덱스 7까지 가져옴
[20, 50]인덱스 생략하기
- 시퀀스객체[:끝인덱스]
>>> a = [0, 10, 20, 30, 40, 50, 60, 70, 80, 90]
>>> a[:7] # 리스트 처음부터 인덱스 6까지 가져옴
[0, 10, 20, 30, 40, 50, 60]- 시퀀스객체[시작인덱스:]
>>> a[7:] # 인덱스 7부터 마지막 요소까지 가져옴
[70, 80, 90]- 시퀀스객체[:]
>>> a[:] # 리스트 전체를 가져옴
[0, 10, 20, 30, 40, 50, 60, 70, 80, 90]- 시퀀스객체[:끝인덱스:증가폭]
>>> a = [0, 10, 20, 30, 40, 50, 60, 70, 80, 90]
>>> a[:7:2] # 리스트의 처음부터 인덱스를 2씩 증가시키면서 인덱스 6까지 가져옴
[0, 20, 40, 60]
- 시퀀스객체[시작인덱스::증가폭]
>>> a[7::2] # 인덱스 7부터 2씩 증가시키면서 리스트의 마지막 요소까지 가져옴
[70, 90]
- 시퀀스객체[::증가폭]
>>> a[::2] # 리스트 전체에서 인덱스 0부터 2씩 증가시키면서 요소를 가져옴
[0, 20, 40, 60, 80]
- 시퀀스객체[::]
>>> a[::] # 리스트 전체를 가져옴
[0, 10, 20, 30, 40, 50, 60, 70, 80, 90]
슬라이스를 사용할 때 인덱스 증가폭을 음수로 지정하면 요소를 뒤에서부터 가져올 수 있습니다.
>>> a = [0, 10, 20, 30, 40, 50, 60, 70, 80, 90]
>>> a[5:1:-1]
[50, 40, 30, 20]
특히 다음과 같이 시작 인덱스와 끝 인덱스를 생략하면서 인덱스 증가폭을 -1로 지정하면 어떻게 될까요? 이때는 리스트 전체에서 인덱스를 1씩 감소시키면서 요소를 가져오므로 리스트를 반대로 뒤집습니다.
>>> a[::-1]
[90, 80, 70, 60, 50, 40, 30, 20, 10, 0]
5) len 응용하기
>>> a = [0, 10, 20, 30, 40, 50, 60, 70, 80, 90]
>>> a[0:len(a)] # 시작 인덱스에 0, 끝 인덱스에 len(a) 지정하여 리스트 전체를 가져옴
[0, 10, 20, 30, 40, 50, 60, 70, 80, 90]
>>> a[:len(a)] # 시작 인덱스 생략, 끝 인덱스에 len(a) 지정하여 리스트 전체를 가져옴
[0, 10, 20, 30, 40, 50, 60, 70, 80, 90]
6) slice 객체 사용하기
파이썬에서는 slice 객체를 사용하여 시퀀스 객체(시퀀스 자료형으로 만든 변수)를 잘라낼 수도 있습니다.
슬라이스객체 = slice(끝인덱스)
슬라이스객체 = slice(시작인덱스, 끝인덱스)
슬라이스객체 = slice(시작인덱스, 끝인덱스, 인덱스증가폭)
시퀀스객체[슬라이스객체]
시퀀스객체.__getitem__(슬라이스객체)
다음과 같이 시퀀스 객체의 [ ](대괄호) 또는 __getitem__ 메서드에 slice 객체를 넣어주면 지정된 범위만큼 잘라내서 새 객체를 만듭니다.
>>> range(10)[slice(4, 7, 2)]
range(4, 7, 2)
>>> range(10).__getitem__(slice(4, 7, 2))
range(4, 7, 2)
물론 slice 객체를 하나만 만든 뒤 여러 시퀀스 객체에 사용하는 방법도 가능합니다.
>>> a = [0, 10, 20, 30, 40, 50, 60, 70, 80, 90]
>>> s = slice(4, 7) # 인덱스 4부터 6까지 자르는 slice 객체 생성
>>> a[s]
[40, 50, 60]
>>> r = range(10)
>>> r[s]
range(4, 7)
>>> hello = 'Hello, world!'
>>> hello[s]
'o, '
7) 슬라이스에 요소 할당하기
- 시퀀스객체[시작인덱스:끝인덱스] = 시퀀스객체
먼저 리스트를 만든 뒤 특정 범위의 요소에 값을 할당해보겠습니다.
>>> a = [0, 10, 20, 30, 40, 50, 60, 70, 80, 90]
>>> a[2:5] = ['a', 'b', 'c'] # 인덱스 2부터 4까지 값 할당
>>> a
[0, 10, 'a', 'b', 'c', 50, 60, 70, 80, 90]
다음과 같이 요소 개수를 맞추지 않아도 알아서 할당됩니다. 만약 할당할 요소 개수가 적으면 그만큼 리스트의 요소 개수도 줄어듭니다.
>>> a = [0, 10, 20, 30, 40, 50, 60, 70, 80, 90]
>>> a[2:5] = ['a'] # 인덱스 2부터 4까지에 값 1개를 할당하여 요소의 개수가 줄어듦
>>> a
[0, 10, 'a', 50, 60, 70, 80, 90]
할당할 요소 개수가 많으면 그만큼 리스트의 요소 개수도 늘어납니다.
>>> a = [0, 10, 20, 30, 40, 50, 60, 70, 80, 90]
>>> a[2:5] = ['a', 'b', 'c', 'd', 'e'] # 인덱스 2부터 4까지 값 5개를 할당하여 요소의 개수가 늘어남
>>> a
[0, 10, 'a', 'b', 'c', 'd', 'e', 50, 60, 70, 80, 90]
슬라이스는 인덱스 증가폭을 지정할 수 있었죠? 이번에는 인덱스 증가폭을 지정하여 인덱스를 건너뛰면서 할당해보겠습니다.
- 시퀀스객체[시작인덱스:끝인덱스:인덱스증가폭] = 시퀀스객체
>>> a = [0, 10, 20, 30, 40, 50, 60, 70, 80, 90]
>>> a[2:8:2] = ['a', 'b', 'c'] # 인덱스 2부터 2씩 증가시키면서 인덱스 7까지 값 할당
>>> a
[0, 10, 'a', 30, 'b', 50, 'c', 70, 80, 90]
인덱스 증가폭을 지정했을 때는 슬라이스 범위의 요소 개수와 할당할 요소 개수가 정확히 일치해야 합니다.
>>> a = [0, 10, 20, 30, 40, 50, 60, 70, 80, 90]
>>> a[2:8:2] = ['a', 'b']
Traceback (most recent call last):
File "<pyshell#1>", line 1, in <module>
a[2:8:2] = ['a', 'b']
ValueError: attempt to assign sequence of size 2 to extended slice of size 3
튜플, range, 문자열은 슬라이스 범위를 지정하더라도 요소를 할당할 수 없습니다.
>>> b = (0, 10, 20, 30, 40, 50, 60, 70, 80, 90)
>>> b[2:5] = ('a', 'b', 'c')
Traceback (most recent call last):
File "<pyshell#2>", line 1, in <module>
b[2:5] = ('a', 'b', 'c')
TypeError: 'tuple' object does not support item assignment
>>> r = range(10)
>>> r[2:5] = range(0, 3)
Traceback (most recent call last):
File "<pyshell#4>", line 1, in <module>
r[2:5] = range(0, 3)
TypeError: 'range' object does not support item assignment
>>> hello = 'Hello, world!'
>>> hello[7:13] = 'Python'
Traceback (most recent call last):
File "<pyshell#6>", line 1, in <module>
hello[7:13] = 'Python'
TypeError: 'str' object does not support item assignment
8) del로 슬라이스 삭제하기
- del 시퀀스객체[시작인덱스:끝인덱스]
다음은 리스트의 인덱스 2부터 4까지 요소를 삭제합니다.
>>> a = [0, 10, 20, 30, 40, 50, 60, 70, 80, 90]
>>> del a[2:5] # 인덱스 2부터 4까지 요소를 삭제
>>> a
[0, 10, 50, 60, 70, 80, 90]
5. 딕셔너리
- 딕셔너리 = {키1: 값1, 키2: 값2}
>>> lux = {'health': 490, 'mana': 334, 'melee': 550, 'armor': 18.72}
>>> lux
{'health': 490, 'mana': 334, 'melee': 550, 'armor': 18.72}
※ 딕셔너리의 키는 문자열뿐만 아니라 정수, 실수, 불도 사용할 수 있으며 자료형을 섞어서 사용해도 됩니다. 그리고 값에는 리스트, 딕셔너리 등을 포함하여 모든 자료형을 사용할 수 있습니다. 단, 키에는 리스트와 딕셔너리를 사용할 수 없습니다.
>>> x = {100: 'hundred', False: 0, 3.5: [3.5, 3.5]}
>>> x
{100: 'hundred', False: 0, 3.5: [3.5, 3.5]}
빈 딕셔너리 만들기
빈 딕셔너리를 만들 때는 { }만 지정하거나 dict를 사용하면 됩니다. 보통은 { }를 주로 사용합니다.
- 딕셔너리 = {}
- 딕셔너리 = dict()
>>> x = {}
>>> x
{}
>>> y = dict()
>>> y
{}
dict로 딕셔너리 만들기
- 딕셔너리 = dict(키1=값1, 키2=값2)
- 딕셔너리 = dict(zip([키1, 키2], [값1, 값2]))
- 딕셔너리 = dict([(키1, 값1), (키2, 값2)])
- 딕셔너리 = dict({키1: 값1, 키2: 값2})
딕셔너리의 키에 접근
- 딕셔너리[키]
>>> lux = {'health': 490, 'mana': 334, 'melee': 550, 'armor': 18.72}
>>> lux['health']
490
>>> lux['armor']
18.72
딕셔너리의 키에 값 할당하기
- 딕셔너리[키] = 값
>>> lux = {'health': 490, 'mana': 334, 'melee': 550, 'armor': 18.72}
>>> lux['health'] = 2037 # 키 'health'의 값을 2037로 변경
>>> lux['mana'] = 1184 # 키 'mana'의 값을 1184로 변경
>>> lux
{'health': 2037, 'mana': 1184, 'melee': 550, 'armor': 18.72}
그럼 없는 키에서 값을 가져오려고 하면 어떻게 될까요?
딕셔너리는 없는 키에서 값을 가져오려고 하면 에러가 발생합니다.
>>> lux = {'health': 490, 'mana': 334, 'melee': 550, 'armor': 18.72}
>>> lux['attack_speed'] # lux에는 'attack_speed' 키가 없음
Traceback (most recent call last):
File "<pyshell#3>", line 1, in <module>
lux['attack_speed']
KeyError: 'attack_speed'
딕셔너리에 키가 있는지 확인하기
- 키 in 딕셔너리
>>> lux = {'health': 490, 'mana': 334, 'melee': 550, 'armor': 18.72}
>>> 'health' in lux
True
>>> 'attack_speed' in lux
False
- 키 not in 딕셔너리
>>> 'attack_speed' not in lux
True
>>> 'health' not in lux
False
이렇게 not in은 특정 키가 없으면 True, 있으면 False가 나옵니다.
딕셔너리의 키 개수 구하기
- len(딕셔너리)
>>> lux = {'health': 490, 'mana': 334, 'melee': 550, 'armor': 18.72}
>>> len(lux)
4
>>> len({'health': 490, 'mana': 334, 'melee': 550, 'armor': 18.72})
4
zip() 기본 문법
zip() 함수는 여러 개의 순회 가능한(iterable) 객체를 인자로 받고, 각 객체가 담고 있는 원소를 튜플의 형태로 차례로 접근할 수 있는 반복자(iterator)를 반환합니다.
>>> numbers = [1, 2, 3]
>>> letters = ["A", "B", "C"]
>>> for pair in zip(numbers, letters):
... print(pair)
...
(1, 'A')
(2, 'B')
(3, 'C')
| 입력 - 두줄 입력받기 | 결과 |
| health health_regen mana mana_regen 575.6 1.7 338.8 1.63 |
{'health': 575.6, 'health_regen': 1.7, 'mana': 338.8, 'mana_regen': 1.63} |
x = input().split()
y = map(float,input().split())
z=dict(zip(x,y))
print(z)
'BASIC' 카테고리의 다른 글
| 리스트 method (1) | 2023.10.09 |
|---|---|
| for 반복문 / while 반복문 / 무한Loop /break, continue (1) | 2023.10.02 |
| 조건문 (0) | 2023.10.02 |
| bool / 비교연산자 / 논리연산자 (0) | 2023.09.29 |
| 연산자 / 변수 (0) | 2023.09.28 |


댓글